Declaración de Conflictos de Interés
El ponente declara no tener conflictos de interés
relacionados con el contenido de este seminario.
Las herramientas mencionadas son de uso personal y código
abierto.
No existe vinculación comercial con ningún proveedor de IA.
Objetivos del Seminario
Al finalizar, serás capaz de:
Soporte al diagnóstico diferencial, interpretación de pruebas, tareas administrativas...
Valoración crítica antes de aplicar respuestas de IA en la práctica clínica.
Método RECORD: distinguir instrucciones eficaces de las que no lo son.
🗺️ Hoja de Ruta: 120 minutos
Haz clic en cualquier bloque para saltar directamente
Bloque 1
Ruptura
15 min
Bloque 2
Fundamentos
45 min
Bloque 3
Demos
40 min
Bloque 4
Práctica
25 min
Bloque 5
Cierre
20 min
Bloque 1: Ruptura
Impacto emocional + Autodiagnóstico
15 minutos
🙋 Pregunta para empezar
¿Has usado alguna herramienta de IA
esta semana
para algo relacionado con tu práctica clínica?
Sí, regularmente
Alguna vez
Nunca
📈 IA en PubMed
De 1 de cada 215 publicaciones
a 1 de cada 90 en dos años
El crecimiento supera al de COVID terapéutica
Dos historias reales
Éxito
Un pediatra genera información para padres sobre gastroenteritis aguda. Revisa, adapta y entrega. Ahorro: 15 minutos.
Bajo riesgo Alto impacto
Fracaso
Un LLM sugiere una dosis de medicación. El clínico no verifica. La referencia citada... no existe.
Alucinación Sin verificación
La diferencia: cómo, cuándo y para qué usamos la herramienta.
Bloque 2A: Fundamentos
Sin lenguaje común, la IA falla en consulta
10 minutos
📚 Nueve conceptos que definen tu relación con la IA
El vocabulario mínimo para evaluar la IA con criterio clínico
LLM
Modelo de lenguaje grande. Predice la siguiente palabra. ChatGPT, Claude, Gemini
Prompt
La instrucción que das a la IA. Calidad output = calidad prompt
IA Generativa
IA que crea contenido nuevo. No busca, genera.
Alucinación
Cuando la IA inventa información falsa. ¡El riesgo crítico!
RAG
IA conectada a fuentes externas. Busca antes de responder. Perplexity, Open Evidence
IA Agéntica
IA que planifica y ejecuta tareas autónomamente. El siguiente nivel.
🏗️ MODELO FUNDACIONAL
Modelo entrenado con datos masivos, adaptable a muchas tareas. Stanford 2021. Clave en el AI Act europeo.
🔤 TOKEN
Unidad mínima que procesa el modelo. Ni letra ni palabra. 1 token ≈ ¾ de palabra
📏 VENTANA DE CONTEXTO
Memoria de trabajo: cuánto puede leer y recordar a la vez. Límite real de la conversación
Implicación clínica: Estos 9 términos aparecerán en cada slide de evidencia. Guárdalos como referencia de trabajo.
La IA puede asistir en las 5 etapas del flujo clínico
GPT-4 aplicable al 71% de subtareas según revisión sistemática 2025
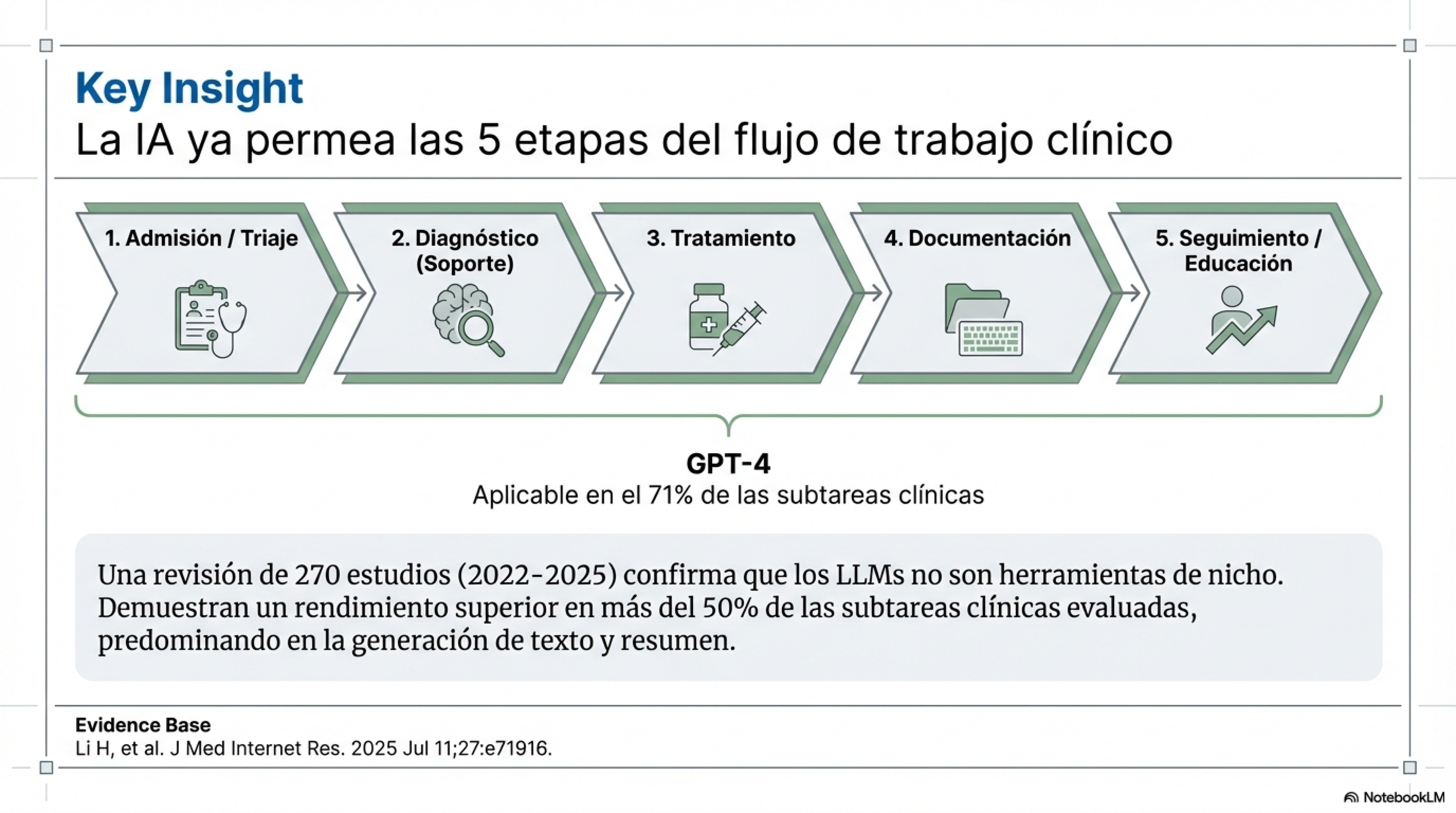
Li H, et al. J Med Internet Res. 2025;27:e71916
Los LLM predicen palabras, no comprenden significados
Large Language Model = sistema que genera texto basándose en patrones estadísticos
Sistema que
predice la siguiente palabra
basándose en patrones estadísticos de billones de textos.
Genera texto coherente
NO comprende
NO razona
Implicación clave: puede generar información falsa con total convicción ("alucinaciones") · Siguiente: evidencia cuantitativa en clínica real
🤔 ¿Has confiado en una herramienta sin verificar?
¿Alguno ha tenido ya una experiencia usando IA en consulta?
Positiva
Negativa
Levantad la mano si queréis compartir (1-2 min)
→ Siguiente: evidencia específica para calibrar dónde confiar
La documentación es la evidencia más sólida
Meta-análisis + IA ambiental: reducción de carga con matices
Reducción de carga administrativa
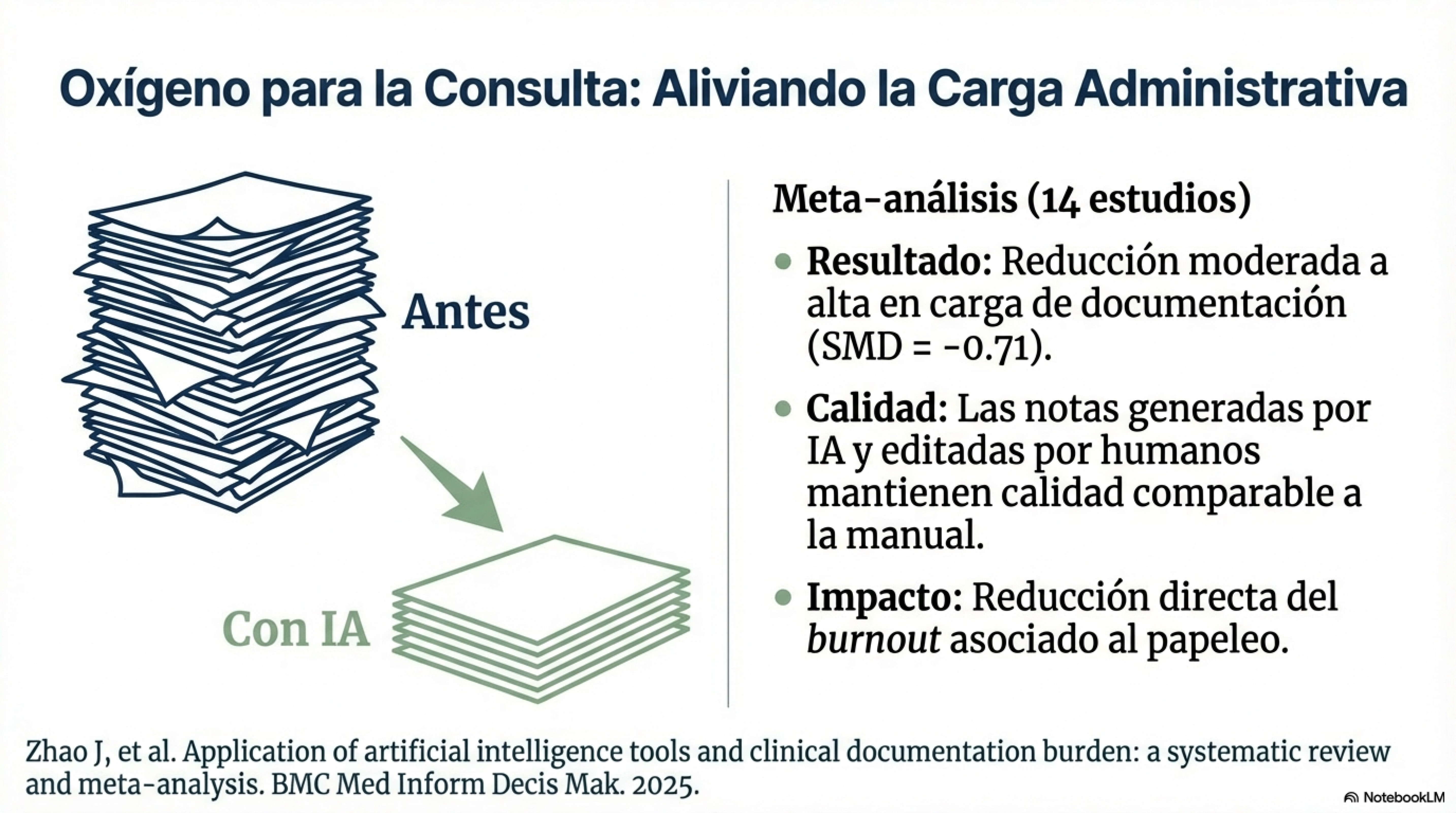
Calidad de notas IA+humano comparable a escritura manual
IA Ambiental: del audio a la nota
Captura conversación (con consentimiento)
Extrae síntomas, signos, diagnósticos
Genera documentación SOAP automáticamente
Requisito ético: consentimiento explícito antes de activar
Paradoja de productividad (Goodson 2025): los clínicos perciben ahorro de tiempo, pero las métricas cuantitativas no siempre lo confirman. Revisar ≠ auditar.
Balance neto: la documentación es la zona verde más clara. 35 pacientes/día × menos tiempo escribiendo = más tiempo mirando al niño.
Zhao et al. BMC Med Inform Decis Mak 2025 · Dave et al. 2025 · Goodson et al. Learn Health Sys 2025
El formato del prompt puede mover precisión hasta 76 pp
58 técnicas documentadas · cuatro con impacto reproducible en resultados clínicos
Chain-of-Thought (CoT)
"Piensa paso a paso" antes de responder
Mejora en GSM8K (Wei et al., NeurIPS 2022)
RAG (Retrieval-Augmented)
Conectar a fuentes verificadas
Reducción de alucinaciones (Lewis et al., 2020)
Few-shot
Dar 2-3 ejemplos antes de la consulta. El formato importa más que las etiquetas.
Self-Consistency
Generar múltiples respuestas y votar la más frecuente (+17,9pp).
Atención: Cambios triviales (espaciado, puntuación) causan variaciones de hasta 76pp en precisión (Sclar et al., ICLR 2024)
Wei 2022 · Kojima 2022 · Wang 2023 · Sclar 2024 · Schulhoff 2024
Un asistente preconfigurado elimina el prompting repetitivo
GPTs (ChatGPT) · Gems (Gemini) · Proyectos (Claude)
Ejemplos para tu consulta
Traductor clínico: convierte analíticas en lenguaje para padres
Codificador CIE-10: sugiere códigos a partir de tu texto libre
Preparador de sesiones: estructura casos clínicos para docencia
Revisor de informes: detecta inconsistencias y sugiere ampliación
Créalo en 3 pasos
1
Define rol + contexto
Usa RECORD o Callens como plantilla
2
Sube documentos de referencia
Protocolos, guías, formularios propios
3
Prueba con casos reales y ajusta
Iterativo — no sale perfecto a la primera
Limitación clave: Un GPT/Gem hereda las alucinaciones del modelo base — pero con tu formato, lo que las hace más creíbles y potencialmente más peligrosas
Bloque 3: Demos en Vivo
La IA como asistente cognitivo: consumir ciencia, producir formatos, elegir herramienta
~12 minutos
NotebookLM: de tus fuentes a podcast, vídeo y presentación
Asistente cognitivo RAG de Google · Solo genera desde tus documentos · Gratuito
NotebookLM
RAG puro: solo genera desde tus fuentes
Clic: ver interfaz
Podcast · Spotify
"Tu dosis periódica de evidencia científica"
Podcast · PubMed RS/MA
12 patologías pediátricas · Último mes · Países OCDE · Ver búsqueda
Presentación
Diapositivas para sesión clínica · Google Drive
Vídeo
Resumen visual narrado · YouTube
Cada cita incluye artículo y revista de origen · No alucina fuera de lo que le das · Verificable
Google NotebookLM · notebooklm.google.com · Gratuito · Máx. 50 fuentes por notebook
Bloque 4: Práctica Dirigida
Ejercicio RECORD
20 minutos
Estructurar el prompt no es opcional
Tres marcos, un mismo principio · La evidencia respalda cada componente
🔗 Chain-of-Thought
Razonamiento paso a paso → mejora consistente en tareas diagnósticas complejas
📋 Few-Shot Prompting
1–2 ejemplos de formato → 94–100% precisión en evaluación de inmunoterapia
🛡️ RAG (fuentes verificadas)
+13% precisión media · −12 a 18% alucinaciones
📝 Prompt estructurado
Adherencia a protocolo: 32% → 100% · Mismo modelo, distinta pregunta
Tres marcos, mismos principios
| Componente | RTF | BRAIN | RECORD |
|---|---|---|---|
| Rol / perspectiva | ✅ R | ✅ R | ✅ R |
| Contexto clínico | — | ✅ B | ✅ E+C |
| Tarea / objetivo | ✅ T | ✅ A | ✅ O |
| Restricciones | — | ✅ I | ✅ R |
| Formato salida | ✅ F | ✅ N | ✅ D |
| Escenario AP | — | — | ✅ E |
RTF: tareas simples · BRAIN: razonamiento diagnóstico · RECORD: pediatría AP
Callens S. Acta Clin Belg. 2026. doi:10.1080/17843286.2026.2613903 · Liu et al. JMIR 2025;27:e72644
Bloque 5: Cierre
Lo que nos llevamos para casa
10 minutos
📋 Pregunta de Evaluación 1
Al considerar el uso de una IA generativa como herramienta de apoyo en Pediatría de AP, ¿cuál representa su aplicación más segura?
- Sustituir la consulta con un especialista en dermatología atípica
- Prescribir de forma autónoma el tratamiento para un lactante febril
- Establecer el diagnóstico definitivo en sospecha de TDAH
- Interpretar una espirometría compleja sin validación
- Generar un borrador de información para padres sobre GEA
✓ Respuesta: 5 — Bajo riesgo clínico, alto valor comunicativo, siempre con revisión del pediatra antes de entregar.
📋 Pregunta de Evaluación 2
Según la paradoja "H+IA" presentada en el seminario, ¿cuál es el riesgo principal de añadir supervisión humana a las respuestas de IA?
- Aumentar el coste económico de cada consulta
- Generar falsa confianza sin reducir errores (26-36%)
- Ralentizar excesivamente el flujo de trabajo
- Reducir la autonomía profesional del pediatra
- Crear dependencia tecnológica irreversible
✓ Respuesta: 2 — Meta-análisis Wang 2026: la supervisión humana no siempre mejora los resultados y puede dar falsa seguridad.
🏠 Lo que nos llevamos para casa
Modelo Sándwich
Humano define → IA procesa → Humano verifica. La responsabilidad siempre es tuya.
Marco conceptualMétodo RECORD
Rol · Escenario · Contexto · Objetivo · Restricciones · Diseño. La calidad del output depende del prompt.
Herramienta online · QR 1Pirámide de Evidencia 5.0 + IA
Elige herramienta por nivel de confianza, no por marketing. Trazabilidad ≠ evaluación crítica.
Herramienta online · QR 2Razonamiento Clínico con IA
20 criterios: 10 sobre tu práctica (deskilling, anclaje, complacencia…) + 10 sobre la herramienta (regulación, sesgo, evidencia). Recomendada: 1×/trimestre.
Abrir herramienta · QR 34 recursos · 3 herramientas online · acceso libre en ernestobarrera.github.io
Gracias
"Homines, dum docent, discunt"
La mejor forma de aprender es enseñando
Licencia CC BY-SA 4.0